|
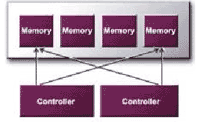
As part of nVIDIA's GeForce4 graphic processing unit (GPU) design, nVIDIA introduces its Lightspeed Memory Architecture II (LMA II) technology. nVIDIA's LMA II implements many patented advancements like: Crossbar Memory Controller, Quad Cache, Lossless Z Compression, Fast Z-Clear, Z-Occlusion Culling, and Auto Pre-Charge. All of which promise to break barriers and free up bottlenecks in memory bandwidth usage. Crossbar Memory Controller Aside from the GPU, another vital component in 3D rendering is its logical memory controller. Because 3D graphics are dependent upon memory bandwidth, inefficient memory usage results in bottlenecks for improved performance. For data that is going to be rendered, the memory controller sends each packet of data in "chunks" of 128-bit to the local memory. Since all data must be sent in predefined packets, the packets are not always being utilized fully every-time. With today's leading 3D applications, the size of a polygon can be very small requiring only about 64-bits of data for each cycle or time it's sent. If you were to use today's popular double-data rate (DDR) ram capable of transferring 256-bit, sending the 64-bit of data in a 256-bit packet would be very inefficient. Only 25% of the packet will be used productively, thus wasting 75% of the memory bandwidth usage. But with nVIDIA's patented Crossbar Memory Controller, multiple crossbar memory controllers can independently or simultaneously work together in delivering packets to multiple memory devices at once. This technology allows memory bandwidth usage to be 2X-4X more efficiently than traditional architectures. The GeForce4 Ti series implements four crossbar memory controllers and the MX series carry two crossbar memory controllers in its GPU.
Quad Cache Quad Cache is a technique that uses four subsystem buffers to rapidly store small amounts of data that will be properly queued and wait for transmission to the memory device. Each one of the four subsystems will have its own unique set of data to store. And since each subsystem stores its own specific data, the memory can pull specific information that it needs from the quad cache subsystems more efficiently and effectively with the need to search for the data. Lossless Z-Compression Z-buffer represents the viewable depth of information for pixels that will be displayed or rendered in a 3D environment. Since the GPU is going to read and write a z-data for every pixel that will be displayed, this makes the Z-buffer one of the largest memory bandwidth users in creating 3D images. With nVIDIA's Lossless Z-Compression, Z-buffer data can be compress to a 4:1 ratio, resizing a chunk of data to ¼ of its original size without any loss of quality to the image when decompressed. This directly results in more efficient memory usage at no degrade in quality. Fast Z-Clear Clearing the Z-buffer is another process that consumes precious memory bandwidth. Traditional architectures require that the GPU go in and write "0" to all the data in the Z-buffer to clear it out which takes time and memory bandwidth. Fast Z-Clear technology effortlessly clears the Z-buffers faster, resulting in an effective 10% increase in frame rates when compared to traditional methods. Visibility Subsystem: Z-Occlusion Culling Z-Occlusion Culling is an advance subsystem that determines what image or pixel is going to be rendered. Traditional architecture methods render all pixels regardless if the pixel is visible or not. Because all pixels will be rendered and half the pixels will not even be seen, the payload on the z-buffer will be tremendously heavy. With the Z-Occlusion Culling subsystem technique, only viewable pixels will be generated and non-viewable pixels will be discarded and will not affect the Z-buffer at all. This smart advance feature will allow up to 50% reduction in memory bandwidth usage in 3D environments. |
 Lightspeed Memory Architecture II
Lightspeed Memory Architecture II